
互联网中对象访问频率的91分布
本文链接: https://blog.openacid.com/tech/zipf/
在互联网领域, 流行着这么一句话:
90%的流量由10%的内容产生.
缓存也由此产生: 只为最频繁访问的10%的内容提供更快的存储, 就可以以很低的成本提供尽可能好的服务质量.
一般符合这种互联网访问模型的曲线是下图这样的. 对每个访问的url做独立计数, 并按照从访问最多到最低排序:
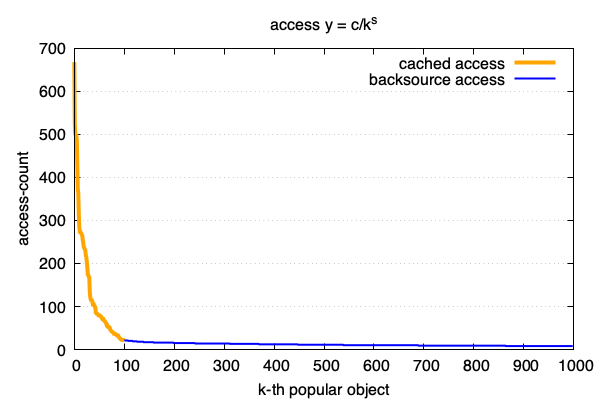
这句是一个经验结论, 从它可以得出我们的频度分布公式: 也就是zipf 模型.
\[f(k) = c/k^s\]这个公式很好, 好就好在可以直接对其左右两边取对数后, 直接转换成了线性关系:
\[log(f(k)) = log(c) - s \times log(k)\]即: k的对数跟y的对数呈现线性关系. 线性太棒了, 简单又好用!
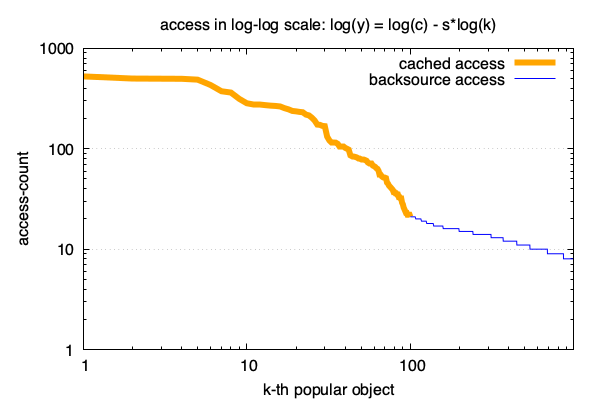
用这个公式我们可以更好的了解和控制数据的访问模型, 做更多的事情. 以下是得出这个结论的愉快的推倒过程.
推倒
首先我们假设, 上面那个比值是p(10%或1%或其他, 根据业务不同而不同),
k个文件中, 最热的pk个文件的访问占比是(1-p),
我们首先假设存在这样一个函数来描述文件热度到文件访问频率的关系:
y=f(k)
那么根据上面的统计规律, 这个函数应该满足这样一个方程:
\[\int_{0}^{pk}f(x) = (1-p)\int_{0}^{k}f(x)\]因为要得到f(k)的函数, 所以对两边对k求个导:
\[p f(pk) = (1-p)f(k)\]好了, 这样一个关系构成了一个数列的递推式. 如果我们先选择曲线上的一个点(k₀, y₀) 满足 \(y_0 = f(k_0)\), 那么根据上面的递推式很容易得到一组都在曲线上的点(kᵢ, yᵢ):
\[k_i = k_0 p^{i-1} \\ y_i = y_0 (\frac{1-p}{p})^{i-1}\]对2个方程都取个对数消去两组数列中的i, 得到kᵢ, yᵢ的关系:
\[\lg y_i = \frac {\lg \frac{1-p}{p}} {\lg p} \lg k_i + (\lg y_0 - \frac{\lg \frac{1-p}{p}}{\lg p} \lg k_0)\]我们再对两边取下指数就可以看到: 基于(k₀, y₀) 选择的这组点是满足 \(y = c/k^s\) 的形式. 目前我们已经可以确定曲线上有一组点集是符合我们的频率分布公式的了, 剩下的点再接着处理一下:
不难看出通过选择不同的(k₀, y₀), 我们可以列出曲线上所有的点, 并且我们还可以看到, 选择不同的(k₀, y₀), 只会性影响这里c的值, 而不会影响a的值. a的值只跟最初选择的p相关. 又因为我们假设整个曲线是平滑的, 直观上就可以得出结论:
所有不同的(k₀, y₀) 确定的曲线的c值是一样的(否则距离很近的2个k₀可以反例出不可导的情况.), 也就是说所有点都在一条\(y = c/k^s\)的曲线上.
在大量的数据统计中s的值不是一个常量, 在比较热的访问中(k比较小的区域),
s一般在0到1之间,
在后面长尾部分, s一般会大于1.
如何将访问计数转换成对应的zipf分布的公式
想要用公式形式\(f(k) = c/k^s\)替代原来的描点描出的曲线, 先要确定式子里面s和c的值
这也很简单, 拿到一段访问日志后, 首先统计独立url计数, 然后 通过多项式回归拟合一条直线
例如我们使用预先准备好的url计数文件 file-access-count.txt 作为例子, 使用这个 find-zipf.py 脚本来拟合:
python2 find-zipf.py
6.796073 - 0.708331x
这样我们就从日志中得到了它的zipf 曲线公式:
\[log(f(k)) = 6.796073 - 0.708331 \times log(k)\]整理成原来的样子, 第k热的对象被访问的次数是:
\[f(k) = \frac {894} {k^{0.708331}}\]标准定义
zipf在标准定义中用全量的相对占比来描述一个对象的访问频率:
\[f(k;s,N)={\frac {1/k^{s}}{\sum \limits_{n=1}^{N}(1/n^{s})}}\]Zipf’s law then predicts that out of a population of N elements, the normalized frequency of elements of rank k, f(k;s,N), is:
有什么用
- 合理配置缓存容量以使缓存成本和性能之间做一个准确的把控.
- 在大量日志分析时, 通过合理近似降低计算量.
- 多了解一些东西. 说不定什么时候就用上了.
我一直觉得, 借来100年的肉身存在在这个世界上的意义, 无非是这3个事儿:
Discover, Design, Distribute
- Discover: 学习和探索, 找到新的东西;
- Design: 如果发现了什么新的东西, 就把它设计出来和实现出来;
- Distribute: 如果实现了什么新的东西, 那就把它带给其他人, 去让他们的生活变得更好.
本文链接: https://blog.openacid.com/tech/zipf/

留下评论